Sora的展示,毫无疑问是吊打此前的runway和pikalabs的。
第六,Sora模型已经可以简单地模拟世界状态的动作。比如说,画家在画布上留下新的笔触,这些笔触会随着时间的推移而持续存在,或者一个人吃汉堡的时候会留下汉堡上的咬痕。有比较乐观的解读认为,这意味着模型具备了一定的通识能力、能“理解”运动中的物理世界,也能够预测到画面的下一步会发生什么。
接下来,我们就来试图回顾一下生成式AI大模型的技术发展之路,以及试图解析一下,Sora的模型是怎么运作的,它到底是不是所谓的“世界模型”?
扩散模型技术路线:GoogleImagen,Runway,PikaLabs
什么是扩散模型?张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
2)扩散过程(也被称为前向过程forwardprocess):扩散过程的目标是让图片变得不清晰,最后变成完全的噪声。
3)反向过程(reverseprocess,又被称为backwarddiffusion):这时候我们会引入“神经网络”,比如说基于卷积神经网络(CNN)的UNet结构,在每个时间步预测“要达到现在这一帧模糊的图像,所添加的噪声”,从而通过去除这种噪声来生成下一帧图像,以此来形成图像的逼真内容。
以上是videotovideo或者是picturetovideo的生成方式,也是runwayGen1的大概底层技术运行方式。如果是要达到输入提示词来达到texttovideo,那么就要多加几个步骤。
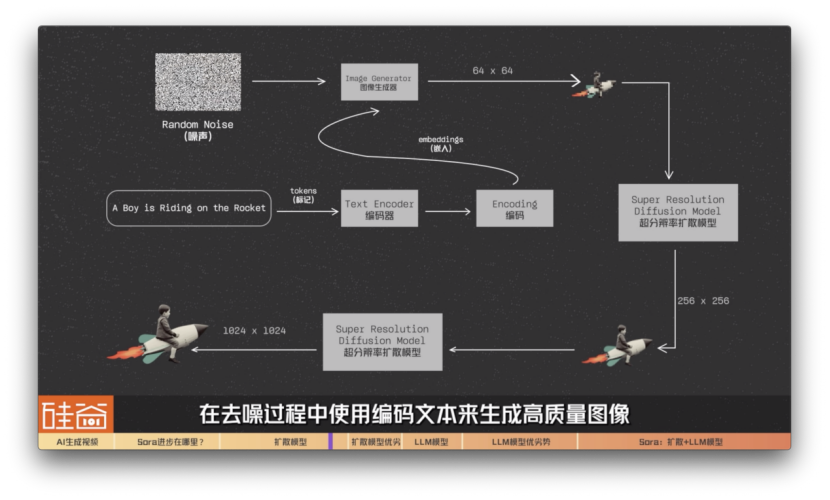
比如说我们拿谷歌在2022年中旬发布的Imagen模型来举例:我们的提示词是aboyisridingontheRocket,骑着火箭的男孩。这段提示词会被转换为tokens(标记)并传递给编码器textencoder。谷歌IMAGEN模型接着用T5-XXLLLM编码器将输入文本编码为嵌入(embeddings)。这些嵌入代表着我们的文本提示词,但是以机器可以理解的方式进行编码。
之后这些“嵌入文本”会被传递给一个图像生成器imagegenerator,这个图像生成器会生成64x64分辨率的低分辨率图像。之后,IMAGEN模型利用超分辨率扩散模型,将图像从64x64升级到256x256,然后再加一层超分辨率扩散模型,最后生成与我们的文本提示紧密结合的1024x1024高质量图像。
简单总结来说,在这个过程中,扩散模型从随机噪声图像开始,在去噪过程中使用编码文本来生成高质量图像。
扩散模型优劣势张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
扩散模型比起之前的GAN等模型来说,有三个主要的优点:
第一,稳定性:训练过程通常更加稳定,不容易陷入模式崩溃或模式塌陷等问题。
第三,无需特定架构:扩散模型不依赖于特定的网络结构,兼容性好,很多不同类型的神经网络都可以拿来用。
然而,扩散模型也有两大主要缺点,包括:
首先,训练成本高:与一些其他生成模型相比,扩散模型的训练可能会比较昂贵,因为它需要在不同噪声程度的情况下学习去燥,需要训练的时间更久。
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
简单来说,基于大语言模型的Videopoet是这样运作的:
先来说说优点:
再来说说缺点:
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
Transformer模型的另外一些问题还包括:
不过说到第五点,我突然想起来最近的这么一个新闻,说谷歌的多模态大模型Gemini中,无论你输入什么人,出来的都是有色人种,包括美国开国元勋,黑人女性版本的教皇,维京人也是有色人种,生成的ElonMusk也是黑人。
这背后的原因可能是谷歌为了更正Transformer架构中的偏见,给加入了AI道德和安全方面的调整指令,结果调过头了,出了这个大乌龙。不过这个事情发生在OpenAI发布了Sora之后,确实又让谷歌被群嘲了一番。
不过,业内人士也指出,以上的这五点问题也不是transformer架构所独有的,目前何生成模型都可能存在这些问题,只是不同模型在不同方向的优劣势稍有不同。
Sora的扩散+大语言模型:1+12?但我们先从Sora公开的这篇技术解析,来看看OpenAI的扩散+大语言模型技术路线是如何操作的。
所以,Sora模型的生成的步骤包括:
第二步:文本理解
第三步:DiffusionTransformer成像
Sora采用了Diffusion和Transformer结合的方式。
目前外界有一些观点猜测,在我们之前说到的扩散模型的第三步骤中,Sora选择将U-Net架构替换成了Transformer架构。这让Diffusion扩散模型作为一个画师开始逆扩散、画画的时候,在消除噪音的过程中,能根据关键词特征值对应的可能性概率,在OpenAI海量的数据库中,找到更贴切的部分,来进行下笔。
我在采访另一位AI从业者的时候,他用了另外一个生动的例子解释这里的区别。他说:“扩散模型预测的是噪音,从某个时间点的画面,减去预测的噪音,得到的就是最原始没有噪音的画面,也就是最终生成的画面。这里更像是雕塑,就像米开朗基罗说的,他只是遵照上帝的旨意将石料上不应该存在的部分去掉,最终他才从中创造出伟大的雕塑作品。而Transformer通过自注意力机制,理解时间线之间的关联,让这尊雕塑从石座上走了下来。”是不是还挺形象的?
说实话,Transformer加扩散模型的方法论并不是OpenAI独创的,在OpenAI发布Sora之前,我们在和张宋扬博士今年一月份采访的时候,他就已经提到说,Transformer加扩散模型的方式已经在行业中开始普遍的被研究了。
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
所以,这也解释了为什么OpenAI现在要发布Sora,其实在OpenAI的论坛上,Sora方澄清说,Sora现在并不是一个成熟的产品,所以,它不是已发布的产品,也不公开,没有等候名单,也没有预计的发布日期。
张宋扬博士,MetaMake-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
以上是我们对Sora非常初步的分析,再次说明一下,因为Sora非常多技术细节没有公开,所以我们的很多分析也是从外部视角去做的一个猜测,如果有不准确的地方,欢迎大家来纠错,指正和探讨。
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系